MySQL LOAD DATA INFILE – import danych z pliku
Do dzisiejszego wpisu zainspirowała mnie moja przyjaciółka, której pomogłem ostatnio w wykonaniu ćwiczenia, polegającego na imporcie danych z pliku tekstowego do tabeli w bazie MySQL. Była to zmodyfikowana wersja jednego z zadań z arkusza maturalnego z informatyki. Jeśli więc kiedykolwiek zastanawialiście się nad możliwością przeniesienia sporej ilości ujednoliconych informacji prosto do bazy danych, to rozwiązanie tej kwestii jest na wyciągnięcie ręki!
Rzut oka na dane i ich strukturę
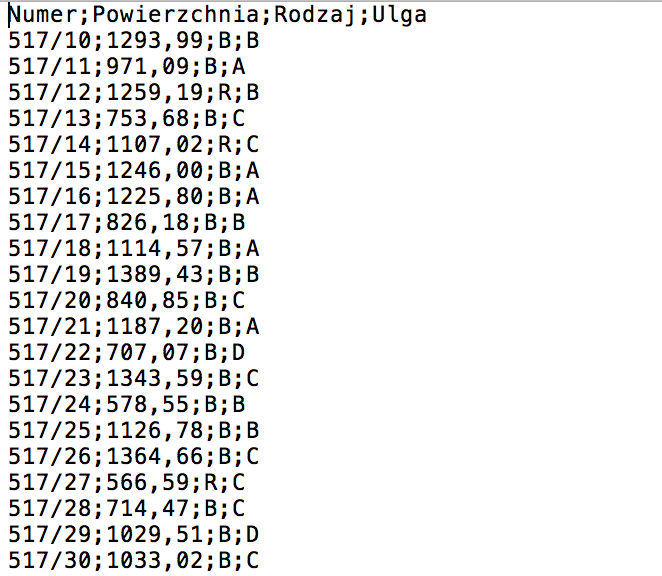
Dane przeznaczone do importu znajdują się w pliku DZIALKI.TXT, który pod względem swojej struktury jest doskonałym przykładem pliku CSV. Separatorem pól jest średnik. Pierwszy wiersz jest wierszem tytułowym, dlatego w późniejszym etapie trzeba będzie go pominąć. Pozostałą część stanowi 5000 elementów do importu. Plik prezentuje się następująco:
Przygotowanie tabeli w bazie danych
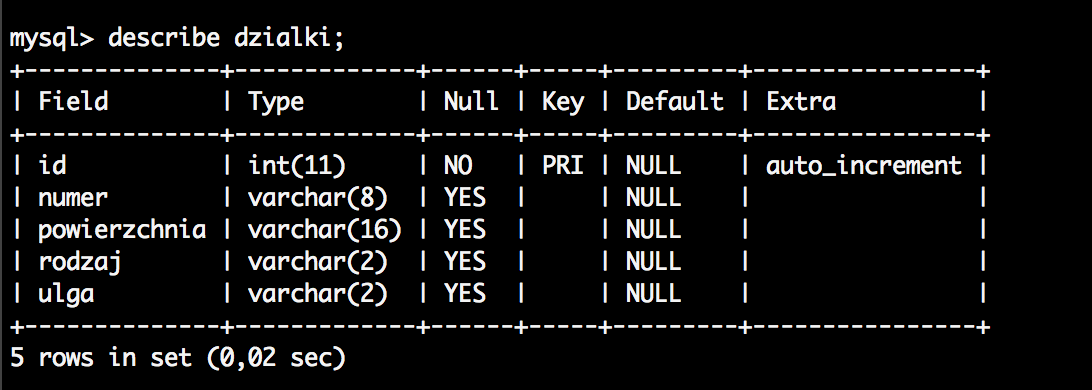
Dane z pliku będziemy importować do tabeli o nazwie „dzialki”. Do pól tabeli dodamy jeszcze pole „id”, które będzie kluczem primary. Struktura tabeli prezentuje się następująco:
Właściwy import danych
Importu dokonamy poleceniem LOAD DATA INFILE:

Krótkie wyjaśnienie składki powyższego polecenia:
- load data local infile – w tym przypadku używamy słowa kluczowego LOCAL, by określić, że plik do importu znajduje się po stronie klienta. Pominięcie tego słowa oznacza, że MySQL będzie szukać pliku wg ścieżki na serwerze, gdzie został uruchomiony.
- Następnie umieszczamy ścieżkę do pliku, uwzględniając użycie (bądź nie) słowa kluczowego LOCAL.
- into table dzialki – określamy nazwę tabeli, gdzie mają trafić wczytane dane. Używamy do tego przygotowanej wcześniej tabeli „dzialki”.
- fields terminated by ‚;’ – określamy separator, po którym rozdzielane są poszczególne pola w wierszu. Domyślnym separatorem jest znak tabulacji (\t).
- lines terminated by ‚\r\n’ – wskazujemy separator, po którym rozdzielane są poszczególne elementy. Domyślnym separatorem jest znak przejścia do nowej linii (\n).
- ignore 1 lines – ignorujemy jedną linię od góry – jest to linia tytułowa, która nie powinna trafić do naszej tabeli.
- Na końcu wyszczególniamy w odpowiedniej kolejności pola tabeli, do których mają trafiać po kolei importowane dane. Jeśli nie zdefiniujemy wykazu pól, wówczas informacje z pliku będą trafiać do tabeli zgodnie z kolejnością pól w tabeli. W takiej sytuacji dodana wcześniej kolumna „id” popsułaby kolejność, tj. numery trafiałyby do kolumny id, powierzchnia do kolumny numer itd.
Rezultaty
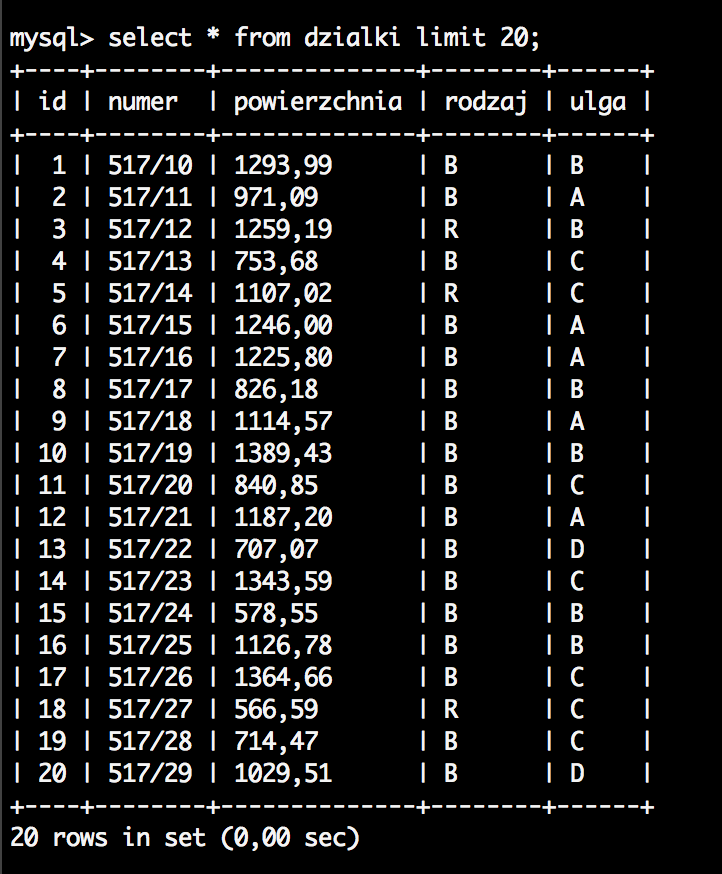
Po wykonaniu polecenia dane powinny zostać prawidłowo dodane do tabeli i prezentować się następująco:
Więcej informacji o LOAD DATA INFILE: